![[AIB]](/aib/wi/aiba12.gif) AIB-WEB. ContributiAIB-WEB. Contributi
AIB-WEB. ContributiAIB-WEB. Contributi
di Vittorio Marino
1 : Le classificazioni gerarchico-enumerative sul Web e la questione dell'incoerenza
2 : Apertura e scalabilità degli schemi a faccette
3 : Applicare la classificazione a faccette sul Web: Epinions.com
4 : "People seem to like FC!": i vantaggi per l'utente
Nella progettazione e nella gestione di un sito web, così come di un qualsiasi sistema informativo digitale complesso (per esempio, un'intranet aziendale o un sistema di knowledge management), i principi della classificazione vengono impiegati in continuazione. Ciò è, in un certo senso, ovvio e necessario. Ci si trova infatti spesso nella situazione di dover organizzare una gran mole di contenuti (informazioni testuali, immagini, materiali sonori, filmati,…) con lo scopo principale di consentirne un facile recupero e, nella maggioranza dei casi, la soluzione più efficace risulta essere quella di ricorrere al buon vecchio metodo della classificazione. Paradossalmente (ma solo in apparenza) ciò avviene nonostante le tante strutture, alcune considerate persino "rivoluzionarie" (si pensi a quella ipertestuale), che un ambiente digitale consente, e nonostante le potenzialità della ricerca attraverso search engine interni.
Ma classificare non è un compito semplice... Un'attività di classificazione non supportata da strategie, metodologie e competenze adeguate rischia di produrre organizzazioni degli item illogiche e incoerenti, quindi poco scalabili e, soprattutto, difficilmente usabili dagli utenti.
L'obiettivo di questo articolo è allora duplice: prima di tutto stimolare, nei "progettisti" e nei content manager del Web e dei sistemi informativi digitali, la consapevolezza di quanto, all'interno del processo più ampio di design, sia importante, necessaria e delicata la fase di classificazione; in secondo luogo, proporre una metodologia di classificazione "più avanzata", di derivazione biblioteconomica (la classificazione a faccette), da impiegare in particolare per la progettazione di sistemi di navigazione migliori.
Si procederà inizialmente a analizzare i difetti più diffusi delle classificazioni gerarchico-enumerative così come realizzate sul Web, dimostrando anche perché sia sconsigliabile utilizzare gli schemi tradizionali della biblioteconomia per organizzare i contenuti dei siti e delle Web directory. Si passerà poi ad esaminare i vantaggi derivanti dall'impiego di un altro strumento sviluppato in campo biblioteconomico, appunto la classificazione a faccette. Tale metodologia di classificazione, in seguito a un'analisi concettuale di un ambito specifico, procede all'individuazione di alcune sue caratteristiche importanti (le faccette), la cui declinazione in classi (foci) permette di descrivere adeguatamente ogni oggetto appartenente al dominio in esame. Applicare tale procedimento di classificazione per organizzare i contenuti di un sito web produce vantaggi sia da un punto di vista interno di indicizzazione e manutenzione (il sistema è aperto, facilmente scalabile, flessibile e adatto alla cross-classification), sia rispetto all'esperienza dell'utente del sito (possibilità di accessi multipli sulla base di diversi bisogni informativi; schema coerente, intuitivo e autoesplicativo; soddisfazione immediata delle esigenze più popolari).
L'uso più evidente sul Web dei principi della classificazione si può riscontrare negli indici sistematici, cioè in quei siti che fungono da cataloghi organizzati delle risorse presenti on-line. Yahoo!, Virgilio, Open Directory, WWW Virtual Library sono tutti esempi di questa tipologia di siti alla quale spesso ci si riferisce anche con i termini di "directory", "indici ragionati", "indici di ricerca per categorie", "subject guide", "subject gateway",... Gli indici sistematici consentono il recupero dell'informazione attraverso la compilazione di un unico schema di classificazione gerarchico-enumerativo e la successiva indicizzazione, sulla base di questo, delle risorse del Web selezionate dagli indicizzatori o proposte per l'inserimento dai responsabili stessi del sito. Compilare schemi enumerativo-gerarchici, selezionare le risorse e indicizzarle secondo una modalità assegnata sistematica: assolutamente nulla di nuovo, quindi, rispetto a come lo strumento della classificazione viene impiegato in biblioteconomia e in molti altri ambiti.
Generalmente tali indici sistematici hanno ripreso dalle classificazioni bibliografiche anche l'approccio semantico: i siti sono infatti raggruppati prevalentemente a seconda dei loro contenuti. Yahoo!, la directory prima per accessi giornalieri, esplicita persino tale scelta: "sites organized by subject".
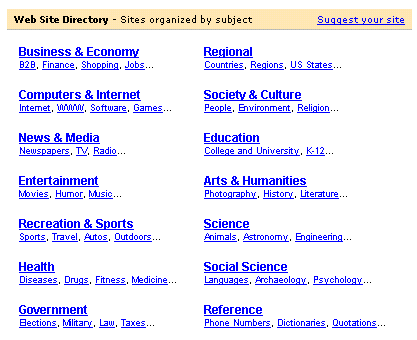
Tuttavia, nonostante tale dichiarazione, l'homepage di Yahoo! integra l'approccio strettamente per contenuti, di fatto dominante, con principi di divisione di tutt'altra specie. Il caso lampante è dato dalla categoria "Regional", in cui i siti sono raggruppati non rispetto al contenuto, ma a seconda della loro collocazione geografica. Nel livello successivo inizia infatti una tassonomia geografica.
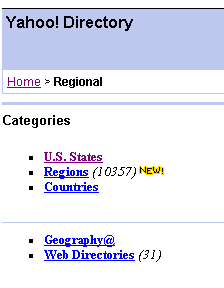
Il problema di un top-level realizzato in questo modo (ma in Yahoo! tale situazione si ripropone anche in altri livelli della sua gerarchia) è che la violazione della regola dell'unico fundamentum divisionis per ogni nodo della classificazione produce categorie non mutuamente esclusive e, quindi, uno schema organizzativo ibrido (più principi di divisione operano contemporaneamente) che è, per sua natura, anche incoerente. Una classificazione ancora più ibrida e incoerente si può ritrovare nell'homepage di Open Directory.
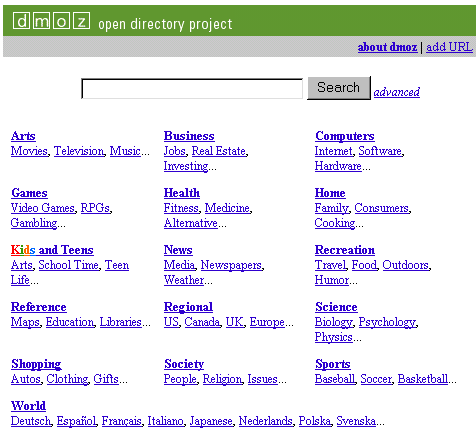
Oltre alla categoria "Regional", sono infatti presenti classi come "Kids and Teens" (classificazione per tipologia di utente), "World" (classificazione per lingua) o "Shopping" (classificazione per attività). Se un utente cerca un sito italiano che gli dia la possibilità di acquistare on-line un gioco per bambini, da quale categoria del top-level di Open Directory deve cominciare? "Shopping", "Kids and Teens", "Games" o "Regional"? È probabile che siano previsti rinvii tra i vari rami di Open Directory e che quindi si riesca ugualmente a arrivare alla categoria desiderata partendo da tutti e quattro i top-level possibili, ma l'imbarazzo causato da tale schema ibrido rimane.
Un'interessante ricerca sui principi di divisione nelle classificazioni del Web è stata realizzata da Zins (2002). Lo studioso, dopo aver analizzato nove siti della rete (portali commerciali, directory, selezioni di risorse da parte di bibliotecari) con lo scopo di dedurne gli schemi organizzativi e il loro livello di "mescolamento", dimostra come "a mixture of categories that reflect different classificatory criteria" (Zins, 2002) sia la norma del Web.
Ma sul Web è necessario impiegare un solo principio di divisione alla volta? In altre parole, la mutua esclusività delle categorie e di conseguenza la coerenza sono proprietà irrinunciabili degli schemi di classificazione del Web? E ancora: il rigore metodologico nella costruzione delle classificazioni, e quindi il rispetto delle regole e dei principi propri di un corretto procedimento classificatorio, sono requisiti fondamentali o si possono mettere da parte a favore di un approccio maggiormente "disinvolto"?
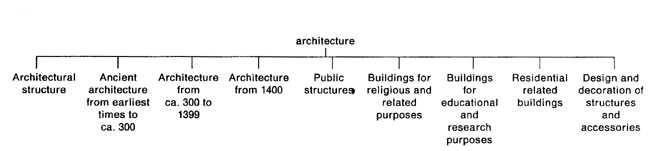
Una parziale risposta a queste domande si può trovare nella teoria e nella prassi bibliotecarie. In biblioteconomia, infatti, il criterio dell'assoluta coerenza delle classificazioni è stato sempre subordinato al "principio pragmatico" secondo il quale è più importante che i sistemi di recupero dell'informazione siano utili agli utenti e facilmente usabili da questi piuttosto che "scientificamente corretti". Serrai (1977) è chiaro a questo proposito: "nessuno ci assicura [...] che i metodi di suddivisione avvengano sempre sulla base di un unico fundamentum divisionis", dato che nelle classificazioni bibliografiche sono state "abbandonate le speranze di beneficiare della precisione e della assolutezza di una divisione logica". Una prova dell'incoerenza anche negli schemi bibliografici si può rintracciare, per esempio, nella divisione della categoria "Architecture" della Classificazione decimale Dewey.
Nonostante tali dipartite, nei sistemi bibliotecari rimane però la tendenza di massima a adoperare per ogni nodo della gerarchia un solo principio di divisione alla volta. Non è un caso che proprio le directory che utilizzano le classificazioni bibliografiche più diffuse (la Classificazione della Library of Congress, la Classificazione decimale Dewey e la Classificazione decimale universale) siano quei siti che, secondo i dati della ricerca di Zins, presentano un numero di principi di divisione minore. Nel Web, invece, il non rispetto di questa regola fondamentale sembra essere costante. Ciò che è grave è che tale violazione avviene anche al top-level, un livello di strategica importanza perché rappresenta l'organizzazione principale e introduttiva del sito.
Se sembra allora essere corretto, in prospettiva utente, rinunciare alle garanzie di una classificazione pienamente logica e scientifica, fino a che punto ciò è tollerabile? In altre parole, qual è il grado di incoerenza ammesso?
L'unico modo per cercare di trovare una risposta a queste domande è quello di tornare nuovamente all'utente per verificare se l'incoerenza degli schemi del Web abbia dei seri risvolti negativi sul recupero dell'informazione e possa essere così causa di ostacoli e difficoltà cognitive nella navigazione. La risposta sembra essere positiva.
Secondo Zins (2002) infatti: "a structured classification scheme helps users to overcome the perplexing effect of the chaotic nature of the Internet by providing a cognitive model of information domain [...]. However, very often a cognitive model of the information domain can be misleading, since it may be based on a biased, illogical, or inconsistent scheme". Anche Rosenfeld e Morville (2002) sono di parere simile: "il potere di uno schema organizzativo puro deriva dalla sua capacità di suggerire un semplice modello mentale che l'utente può facilmente comprendere. Gli utenti riconoscono facilmente un'organizzazione specifica per audience o per argomento e schemi organizzativi puri abbastanza piccoli possono essere applicati a grandi quantità di contenuto senza sacrificarne l'integrità o sminuirne l'usabilità. Tuttavia, quando si inizia a miscelare elementi di molteplici schemi, ne consegue spesso confusione e le soluzioni sono raramente scalabili. Poiché le parti sono mischiate tra loro, non possiamo formarci un modello mentale".
Un sistema coerente è anche maggiormente prevedibile: all'utente potrebbe bastare la lettura di solo alcune classi per dedurre tutte le altre, rendendo così più semplice e più rapida l'attività di comprensione e di apprendimento. A volte, per esempio se l'utente trova subito l'informazione che cercava (magari ancor prima che la pagina si sia completamente caricata!), può capitare che veri e propri modelli mentali non vengano prodotti: "gli utenti decidono molto velocemente quali parti della pagina sembrano avere informazioni utili e poi quasi nemmeno volgono lo sguardo al resto -- quasi come se non ci fosse" (Krug, 2000). Quando modelli mentali sono invece necessari, la rapidità della loro creazione e la prevedibilità del sistema sono aspetti molto importanti.
Rosenfeld e Morville (2002) evitano però di assumere una posizione eccessivamente rigida e ammettono l'uso di schemi incoerenti in due circostanze: se il sito non classifica grosse quantità di contenuto (e questo non è sicuramente il caso delle directory...) o se le categorie create con fundamenta divisionis diversi sono fra loro divise [1].
Nella sezione 4 vedremo come un modo possibile per seguire l'indicazione di Rosenfeld e Morville (2002), e quindi separare le classi generate da criteri di divisione differenti, sia proprio quello di realizzare un sistema basato su una classificazione a faccette. Uno schema di questo tipo ha anche il pregio di esplicitare i principi di divisione adottati, aumentando così l'usabilità della classificazione.
Nella precedente sezione ho dimostrato che:
Ampliando quest'ultimo punto, è importante sottolineare come il minor rigore delle classificazioni realizzate ad hoc per la rete non si riscontri solo nel loro basso livello di coerenza, ma anche nei termini scelti per definire le categorie, nei loro "rozzi accenni di faccettazione" (Gnoli, 2002) e nella frequente scorciatoia di elencare "le suddivisioni di un dato livello [...] in ordine alfabetico anziché sistematico" (Gnoli, 2002). Il giudizio di Santoro (2002) sulle classificazioni home-grown del Web è impietoso: "appaiono quanto mai episodiche, approssimative, estrinseche, programmaticamente lontane dal rigore e dalla sistematicità degli ordinamenti convenzionali". Hunter (2002) le considera alla stregua di "semi-professional attempts to give some subject-based access to Internet resources via hierarchical guides".
Date tali premesse, l'utilizzo anche sul Web delle classificazioni bibliografiche potrebbe sembrare una soluzione ragionevole. Molti studiosi di biblioteconomia hanno in effetti sottolineato come questa sia la strada più corretta da seguire: "it is time to promote our carefully developed, maintained and continuously updated library classification systems as general knowledge organization tools" (Mitchell, 1998). Le argomentazioni portate a sostegno di questa tesi sono assolutamente logiche: se la biblioteconomia ha studiato per secoli i problemi legati all'organizzazione delle conoscenze e ha sviluppato sistemi di classificazione rodati e impiegati in tutto il mondo, perché non utilizzarli anche per il Web, invece di far finta che non esistano e ripartire da zero? Secondo MacLennan (2000), infatti, "the skills in which information workers have traditionally specialized -- identification, acquisition, cataloguing and classification of resources -- would seem to be those which have much to offer [to] the organization of Internet resources, but it appears that, to date, these have not been successfully applied to significant degree", mentre Maltby e Marcella (2000) sottolineano come "some of their practices as well as the classification schemes used have nineteenth-century roots. And many people think of these services as essentially and permanently book-oriented, thus often misunderstanding or seriously underrating the potential contribution of library practitioners to the dynamic information world of today and tomorrow".
All'interno del mondo bibliotecario la ricerca su questi temi è andata anche oltre, cercando di verificare quale degli schemi classificatori classici sia maggiormente adatto al Web (cfr. Saeed e Chaudry, 2001). Per esempio, Vizine-Goetz (1996) dimostra come la Classificazione della Library of Congress e la Classificazione decimale Dewey prevedano una copertura di argomenti sufficientemente ampia per classificare le risorse di Internet. Nel proporre per il Web le classificazioni bibliografiche i bibliotecari sono comunque consapevoli del fatto che accorgimenti e modifiche all'impianto tradizionale debbano essere necessariamente apportati, non fosse altro che per la sostanziale diversità tra la fisicità del libro e la virtualità del Web (cfr. Newton, 2000).
Tuttavia, nonostante questo coro a favore, i "vecchi" schemi bibliografici sono stati anche aspramente criticati: Steinberg (1996) li descrive come "antiquated and inadequate", mentre Weinberg (1996) considera l'epistemologia accademica per disciplina della Classificazione Dewey non adatta al Web, preferendo un'organizzazione per argomenti concreti.
Ma le classificazioni bibliografiche classiche, in quanto enumerative e condivise, soffrono soprattutto di un altro problema: sono di fatto conservative perché strutturalmente chiuse, istituzionalizzate e centralizzate. Gli schemi tradizionali della biblioteconomia non consentono infatti in fase di indicizzazione, quando diviene necessario, l'inserimento da parte del classificatore di una nuova categoria. Solo il compilatore può modificare la classificazione, redigendo un foglio di revisione ufficiale o pubblicando un'edizione successiva dello schema. Ciò può avvenire anche a distanza di molti anni: tempi troppo lunghi per il Web, ma ormai anche per le stesse biblioteche [2]. Aspettando una revisione o una nuova edizione, il materiale che non trova una giusta collocazione viene indicizzato in una classe "di compromesso" e, quindi, in modo non completamente adeguato.
Nel caso però di schemi di classificazione enumerativi creati e mantenuti localmente da una singola istituzione, i tempi di aggiornamento possono essere più rapidi. Per rendere più rapido e adattabile il sistema, i responsabili dei siti hanno allora optato per classificazioni home-grown: nel caso sia necessario, nuove sottocategorie sono create e quelle precedenti modificate. Tutto ciò non sarebbe possibile se, per esempio, Yahoo! dovesse seguire fedelmente le indicazioni dettate da uno schema tradizionale, condiviso, istituzionalizzato e centralizzato [3].
Le classificazioni home-grown del Web hanno quindi trovato una soluzione pragmatica alla questione della chiusura, ma sarebbe tuttavia un grave errore concettuale considerarle sistemi aperti. Uno schema realmente aperto permette anche al classificatore, e non solo al compilatore, di poter generare nuove categorie. Invece, anche nelle classificazioni home-grown (del Web e delle istituzioni che adottano uno schema internamente compilato), il classificatore continua a non avere alcuna autonomia in fase di indicizzazione e il ricorso a un compilatore che modifichi lo schema è indispensabile. La maggiore adattabilità delle classificazioni home-grown del Web non è infatti garantita da novità e miglioramenti concettuali e dall'uso di tecniche di classificazione più sofisticate come, per esempio, la generazione sintetica delle categorie. Il loro impianto di base rimane assolutamente tradizionale, quindi strettamente enumerativo, gerarchico e chiuso. Rari sono i sistemi di sintesi previsti, oltretutto inferiori e "rozzi" (Gnoli, 2002) rispetto a quelli delle revisioni più recenti di alcuni schemi classici. Il vantaggio nella maggiore rapidità dei cambiamenti, che mostrano rispetto alle classificazioni bibliografiche condivise, è dovuto a fattori esterni, in un certo senso prettamente organizzativi: è solo la loro natura home-grown che permette ai compilatori di modificare la gerarchia in qualsiasi momento.
Ben diverso è il caso delle classificazioni analitico-sintetiche (o a faccette), le quali consentono un'effettiva apertura grazie a innovazioni sostanziali nel procedimento stesso di classificazione. Tali sistemi, dichiaratamente alternativi agli schemi gerarchico-enumerativi tradizionali, sono infatti frutto di un ripensamento radicale delle tecniche di classificazione: abbandonando l'idea di un'enumerazione a priori di tutte le classi a favore di una metodologia che consente di creare le categorie "on the fly" partendo da alcuni elementi preventivamente decisi (le faccette e i foci), si assicura finalmente anche al classificatore, in fase di indicizzazione del materiale, la possibilità di generare le classi di cui ha bisogno.
Un sistema on-line basato su una classificazione a faccette, in quanto effettivamente aperto, è quindi una soluzione interessante per andare incontro alla necessità, così urgente sul Web, di poter fare affidamento su schemi di classificazione flessibili e velocemente adattabili.
Non si deve però cadere nell'errore di considerare tale apertura assoluta. È infatti chiaro che il numero di categorie potenziali previste ha un limite che, sebbene molto elevato, rappresenta in ogni caso un vincolo nelle capacità rappresentative del sistema. Ma gli schemi a faccette rimediano a questo problema attraverso un alto livello di scalabilità, assai maggiore rispetto alle classificazioni gerarchico-enumerative classiche (sia condivise, sia home-grown). Queste ultime sono infatti difficilmente scalabili: l'aggiunta di una nuova categoria rende spesso necessaria la modifica delle classi dello stesso livello (per assicurarne la mutua esclusività) e/o di una grossa parte della struttura ad albero dello schema. La colpa di tale (ennesimo...) difetto delle classificazioni gerarchico-enumerative è da imputare anche alla loro struttura gerarchica. In uno schema ad albero tradizionale ci sono infatti forti relazioni per ogni ramo: le classi inferiori dipendono da quelle superiori. Negli schemi a faccette è invece "sempre possibile aggiungere una nuova faccetta descrittiva di un nuovo aspetto dell'oggetto" (Rosati, 2003) e non si avranno ripercussioni di alcun tipo sulle altre faccette (il criterio della mutua esclusività tra le faccette deve però essere sempre garantito). In una classificazione analitico-sintetica ogni faccetta è infatti autonoma dalle altre: determina una proprietà ("sfaccettatura") dell'oggetto da classificare indipendentemente dalle proprietà descritte dalle altre faccette.
Non tutto è però così roseo come sembra... Se il sistema può accogliere nuove faccette senza doversi "aggiustare" globalmente, ed è quindi intrinsecamente scalabile, si ripropone tuttavia anche in questo caso, così come per le classificazioni gerarchico-enumerative, la questione della riclassificazione. L'aggiunta di una faccetta rende infatti necessaria la riclassificazione di tutte le entità secondo la nuova faccetta e, quando migliaia sono gli oggetti già classificati, il lavoro non è certo di poco conto... Tale riclassificazione assume connotati ancora più gravi persino di quelli causati nelle classificazioni gerarchico-enumerative: l'inserimento di una nuova categoria in uno schema gerarchico richiede generalmente la riclassificazione solo di una zona circoscritta della struttura ad albero dello schema. È però evidente come l'aggiunta di una faccetta abbia vantaggi di gran lunga superiori rispetto all'inserimento o alla modifica di una o più categorie in uno schema gerarchico. Una faccetta in più determina infatti un aumento esponenziale del numero delle combinazioni potenziali e, quindi, un livello di specificazione maggiore del carattere descrittivo delle classi.
Cosa comporta, invece, l'introduzione, anch'essa chiaramente possibile, di un nuovo focus in una faccetta? I problemi si avranno se l'aggiunta di un nuovo focus rende non mutuamente esclusive le classi: essendo queste parte di una precisa tassonomia costruita sulla base del principio di divisione della faccetta, si ripropongono infatti gli stessi problemi di inserimento e di riclassificazione tipici delle classificazioni gerarchico-enumerative: la riclassificazione del materiale non riguarderà tutti gli item, ma è tuttavia probabile per una parte di questi.
È consigliabile allora prestare sempre molta attenzione (e tempo) alla preliminare analisi a faccette: tale fase è infatti di strategica importanza nello sviluppo di un sistema di classificazione analitico-sintetico e, se compiuta con cura, evita poi problemi di riclassificazione.
Un sito che fa uso delle tecniche di classificazione analitico-sintetiche è Epinions.com. Sul Web è possibile trovare anche altri esempi di implementazione di schemi a faccette, con una varietà stimolante di interfacce proposte: Epicurios.com, che utilizza la faccettazione per classificare le ricette gastronomiche, Wine.com, l'esempio sempre citato nella letteratura sull'argomento, e New York City Search, una guida di New York che impiega le faccette per aiutare la ricerca in alcune sue categorie (ristoranti, eventi, ...). Sebbene sarebbe interessante analizzare ognuno di questi siti per evidenziare le peculiarità, i pregi e gli eventuali difetti dei loro sistemi a faccette, in questa articolo ci soffermeremo prevalentemente su Epinions.com, probabilmente l'esempio più riuscito e chiaro.
Epinions.com è un sito che offre la possibilità di confrontare i prezzi di un determinato prodotto venduto dai maggiori siti di e-commerce. L'obiettivo è quello di aiutare i consumatori a scegliere il sito che lo vende a prezzo minore. A una prima occhiata, l'homepage di Epinions.com non presenta sostanziali differenze con quella che è la prassi in molti siti del Web, e anche lo schema di classificazione appare essere tipicamente enumerativo e gerarchico.
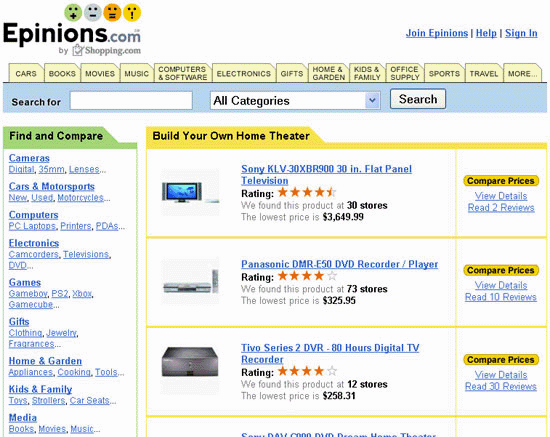
Inoltre, osservando le sottocategorie, sembrerebbe di trovarci ancora a che fare con le "solite" classificazioni incoerenti del Web: categorie prodotte con criteri diversi ("Computers", "Kids & Family", "Gifts") o fra loro sovrapposte ("Electronics" e "Cameras"). Lo schema sembra essere anche molto arbitrario e soggettivo: perché i vestiti sono considerati solo alla stregua di regali? Perché non inserire piuttosto i giocattoli all'interno di questa categoria?
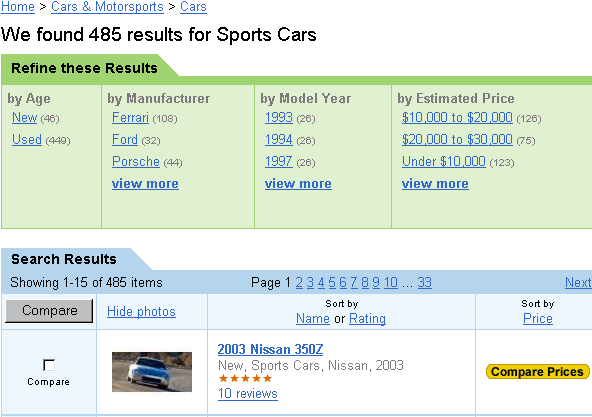
Il sistema a faccette di Epinions.com "esplode" però se si scende nei livelli più bassi della gerarchia. Per esempio, se si clicca prima su "Cars & Motorsports" e poi su "Cars by Type", compare la schermata seguente:

Sono mostrate tutte le faccette previste per la categoria "Cars" ("Type", "Manufacturer", "Age", "Model Year" e "Fuel Type") con alcuni loro foci (per vedere tutti i foci di ognuna delle faccette basta cliccare su "view more"); tra parentesi viene indicato il numero degli item di ogni focus. Da questo momento in poi la navigazione che l'utente può effettuare sarà esclusivamente per faccette: può partire da uno dei foci della faccetta che maggiormente gli interessa, andando poi, se lo considera necessario, a ridurre (raffinare) il numero degli item che gli appariranno aggiungendo man mano nuovi foci. L'utente può facilmente prevedere se gli conviene, e come, proseguire nel filtraggio. Accanto ai foci sono infatti sempre indicati i numeri di item che verranno recuperati applicando quel dato focus: delle sorte di affordance che servono a "rendere visibile il compito" (Scalisi, 2001) segnalando all'utente cosa può continuare a fare [4].
Un item può inoltre presentare, se necessario, più foci per la stessa faccetta, risolvendo così l'imbarazzo, tipico nelle classificazioni gerarchico-enumerative, di non sapere dove collocare, per esempio, un'automobile che è allo stesso tempo sport car, convertible e compact car. Nel mondo "fisico" questo è uno dei problemi più stringenti: in una biblioteca non è ovviamente possibile collocare uno stesso libro su diversi scaffali ed è anche improponibile, per evidenti ragioni logistiche e economiche, l'opzione di comprare uno stesso libro in più esemplari. Nella prassi biblioteconomica non è nemmeno una soluzione molto diffusa, anche se sarebbe auspicabile in alcune situazioni, replicare le ben più piccole schede cartacee sotto diversi soggetti. Il Web, come qualunque altro sistema digitale, può ovviare a questo problema replicando lo stesso item in diverse posizioni della struttura gerarchica (la virtualità lo consente...), ma è tuttavia evidente come la soluzione ottenibile con una classificazione a faccette sia molto più efficace e elegante. In uno schema enumerativo-gerarchico, infatti, la classificazione di un item in più classi (cross-classification), se a volte è utile e necessaria (per esempio, le categorie dello schema sono mutuamente esclusive, ma l'item presenta le caratteristiche di entrambe le classi ed è quindi probabile che venga cercato dagli utenti in tutte e due), crea però gravi problemi nel caso sia effettuata troppo spesso e in modo "disinvolto". Si rischia di far crollare l'usabilità di tutto lo schema in quanto l'utente non comprende più come sono ordinati gli item e, di conseguenza, non riesce a costruirsi un modello mentale dell'organizzazione del sito: "a high level of redundancy makes it very difficult for users to learn to differentiate one category from another" (Risden, 1999). In un'indicizzazione a faccette questo problema non sussiste perché più che collocare item in box predefiniti, li si descrive tramite foci, e le descrizioni non presentano limiti così rigidi.
Il sistema di classificazione di Epinions.com prevede quindi nel complesso l'integrazione tra una classificazione gerarchico-enumerativa classica e una a faccette. La prima risulta avere una funzione esclusivamente introduttiva alla seconda. Queste due tecniche sono applicate in contesti distinti e solo in alcuni casi tendono a sovrapporsi. I prodotti sono infatti preliminarmente divisi in macrocategorie e, solo quando si è arrivati a item considerati sufficientemente specifici (Cars, Video-games, Office Machines, Printers, Books, Hotels & Resorts), parte la classificazione a faccette.
L'opzione di non adottare metodi di classificazione analitico-sintetici già dall'homepage, ma solo nelle categorie con precise tipologie di prodotto, è stata giustamente scelta perché in questo modo le faccette possono essere più specifiche, risultando di maggiore utilità per l'utente. "Resolution" e "Optical Zoom" sono faccette adatte a descrivere le telecamere digitali, "Record Label" i dischi, "Fuel Type" le automobili, "Screen Size" i televisori, ma non sono adeguate a classificare tutti i prodotti in generale. Faccette comuni a varie tipologie di prodotto sarebbero vaghe, inutili e causerebbero una proliferazione senza controllo di foci. Le classificazioni a faccette sono quindi difficilmente utilizzabili se gli item sono molto eterogenei (questo è uno dei limiti maggiori dell'approccio analitico-sintetico) e l'integrazione tra i due approcci di classificazione risulta essere necessaria in alcune situazioni. Non a caso un sito che utilizza un sistema a faccette già a partire dall'homepage è Wine.com. Ciò gli è consentito perché su questo sito si può comprare solo vino (e accessori correlati). Le tre faccette previste per iniziare la navigazione dall'homepage sono: "Region", "Type" e "Winery".
D'altronde, anche il top-level dello schema bibliografico generale analitico-sintetico sviluppato da Ranganathan (la Classificazione Colon) presenta una classificazione enumerativa introduttiva a quella per faccette: le classi principali della Colon sono infatti le tradizionali discipline degli schemi bibliografici classici. Gli sviluppi bibliotecari più interessanti della teoria della faccettazione si sono inoltre avuti proprio nella compilazione delle classificazioni speciali (grazie soprattutto al lavoro del Classification Research Group) : l'omogeneità nei contenuti del materiale bibliografico che tali classificazioni devono indicizzare permette infatti faccette molto specifiche .
Nella sezione 2 sono stati dimostrati i vantaggi che l'adozione sul Web di uno schema a faccette può comportare per il lavoro dei designer e degli architetti dell'informazione di un sito, consentendo loro di fare affidamento su un sistema aperto, facilmente scalabile e flessibile in fase di indicizzazione. Inoltre, come abbiamo visto nella sezione precedente, in una classificazione analitico-sintetica la tecnica della cross-classification è applicabile senza generare confusione nello schema e negli utenti. Uno sistema a faccette garantisce quindi anche sul Web possibilità di classificazione più sofisticate. Ma l'esperienza dell'utente che effettua ricerche e navigazioni "esplorative" in interfacce a faccette viene sensibilmente migliorata o i vantaggi sono solo da un punto di vista interno di gestione e manutenzione dello schema stesso?
Sfortunatamente, data anche la novità delle classificazioni analitico-sintetiche sul Web, non è ancora disponibile un corpus sostanzioso e ufficiale di test di usabilità che ne dimostrino le prestazioni. È tuttavia possibile trovare qualche notizia ufficiosa nei gruppi di discussione on-line o nei siti che affrontano questo tipo di argomenti. Per esempio, su uno Yahoo! Group dedicato esclusivamente alle questioni legate alla classificazione a faccette <http://groups.yahoo.com/group/facetedclassification> è possibile leggere un messaggio in cui Josh Porter afferma che: "I've been testing a lot of sites that use FC lately during my work at User Interface Engineering. We have been VERY impressed with the sites that use faceted classification. As mentioned before, Endeca uses FC and their sites have performed remarkably well [...] People seem to like FC!" <http://article.gmane.org/gmane.comp.infodesign.facetedclassification/37>.
Quali caratteristiche delle interfacce a faccette le rendono allora così usabili e utili per gli utenti? Per esaminare i vantaggi degli schemi a faccette sul Web in una prospettiva di esperienza-utente è necessario ritornare alla "questione dell'incoerenza" esposta nella sezione 1, e chiederci perché i siti web facciano così ampio uso di classificazioni altamente ibride e incoerenti nonostante le difficoltà che queste possono comportare per l'utente.
Il motivo principale di tale utilizzo può essere fatto risalire alla necessità di inserire nel top-level della gerarchia (e quindi in homepage) il numero più alto possibile di "categorie popolari", attuando così una strategia di "popularity-based classification" (Knowledge Management Connection, 2002). Lo scopo è quello di consentire all'utente un accesso più veloce a tali "categorie popolari", intendendo con questa espressione gli argomenti, i servizi, le azioni, i prodotti, e in generale tutti gli item classificati, che sono considerati più rilevanti per le tipologie di utente a cui il sito si rivolge.
Uno schema di classificazione rigorosamente coerente può comportare il rischio che alcune categorie ritenute popolari, o addirittura tutte, siano collocate in nodi inferiori e diversi dello schema, causando così sia un aumento delle difficoltà nel loro ritrovamento da parte dell'utente, sia la necessità di un numero di click maggiore rispetto all'ipotesi in cui tali categorie fossero direttamente disponibili in homepage. Se l'obiettivo è realizzare una "popularity-based classification", spesso risulta allora essere necessario rinunciare alla coerenza dello schema (mutua esclusività delle categorie e adozione di un unico principio di divisione per nodo). In una struttura gerarchico-enumerativa, la progettazione di una "popularity-based classification" può infatti implicare che le categorie del top-level:
Di fatto, attraverso una "popularity-based classification", i siti web cercano di soddisfare già in homepage molti dei bisogni informativi e delle esigenze dei loro potenziali utenti. Sanno benissimo, nonostante a dir la verità non ci sia un totale accordo su questo tema [6], che al navigatore del Web non piace fare molti click per arrivare a ciò che cerca. Sanno anche che uno schema di classificazione è sempre soggettivo e arbitrario: orientarsi nelle tassonomie compilate da altri non è spesso semplice. Se l'utente trova soddisfazione alle sue esigenze subito, la sua esperienza sarà verosimilmente meno traumatica.
Accettando l'ipotesi che questa sia la strategia di base adottata anche dagli indici sistematici e dai portali della rete, è ora possibile comprendere meglio il motivo che ha spinto Yahoo! a introdurre nel suo top-level la categoria "Regional" (cfr. sez. 1). Se l'obbiettivo è soddisfare in homepage tutte le esigenze più rilevanti, la ricerca per collocazione geografica non può di certo mancare essendo una strategia ottimale e desiderata dagli utenti in molti casi. Si badi però che in questo caso è stato inserito, più che una categoria popolare, un principio di divisione alternativo che consente di navigare l'indice secondo una differente modalità. Ciò è reso ancora più chiaro dall'etichetta "By Region" che troviamo in altre sottocategorie di Yahoo!. Tale approccio è quindi concettualmente differente rispetto a quello alla base delle categorie di Open Directory "Games" e "Shopping", sebbene anche quest'ultima sia generata da un principio di divisione diverso da quello dominante. Nel caso di "Regional" assistiamo infatti a un vero e proprio cambio di paradigma: le esigenze degli utenti non sono più soddisfatte prevedendo percorsi gerarchici che li portino al particolare item cercato nel modo più rapido possibile (quindi facendo salire in homepage le categorie popolari), ma consentendo loro di navigare sulla base di logiche diverse un set specifico di risorse.
Tale secondo approccio è efficace perché tiene conto di uno dei possibili fattori alla base delle differenze nelle esigenze di recupero. Le strategie di ricerca si possono infatti diversificare anche per un'ineguale considerazione, da parte degli utenti, del grado di priorità nelle caratteristiche di una specifica tipologia di item. Mi spiego meglio riportando un esempio "dal mondo reale" tratto da un articolo di Jeff Veen (2002): "a couple weeks ago, I walked into a huge warehouse of kitchen appliances and was approached by a salesman. "Can I help you?" he asked. "I need a dishwasher that is energy and water efficient with stainless steel tub and accepts cabinet fronts for an integrated look" I told him smugly. "We have three" he replied. "How much do you want to spend?". Now that's a good salesman. He had the entire warehouse inventory in his head, and could narrow down my search based on the criteria I specified. He even knew which unspecified attributes (price) might be important to my decision. If only Web sites were as effective. Based on my personal preferences, a typical navigation system for dishwashers might look like this: appliances > dishwashers > energy consumption". L'ordine nelle categorie delle caratteristiche preferite da Jeff Veen dovrebbe continuare con un livello in cui le lavastoviglie sono divise per aspetto esteriore e poi con un altro in cui sono raggruppate per prezzo. Solo una sequenza di questo tipo, che riflette in pieno i bisogni specifici di Jeff Veen, renderebbe la sua ricerca soddisfacente al 100%. È però evidente come l'ordine in questa gerarchia di classificazione coerente sia assai idiosincratico e rischi quindi di non soddisfare le esigenze di ricerca di altri utenti: ci sarà sicuramente chi darà una priorità maggiore al prezzo, chi all'aspetto esteriore,... Emergono chiaramente i problemi tipici causati dall'unidimensionalità delle classificazioni gerarchico-enumerative coerenti, le quali necessariamente danno una priorità vincolante alla prima caratteristica di divisione scelta dato che è solo a partire da questa, o meglio dalle classi generate applicandola, che può iniziare l'ulteriore suddivisione in sottoclassi, utilizzando magari un diverso criterio di divisione per visualizzare altre relazioni tra gli oggetti. Ciò determina una rigidità di accesso che rappresenta un forte limite nelle ricerche effettuate attraverso schemi gerarchico-enumerativi.
Riassumendo, le classificazioni gerarchico-enumerative pienamente coerenti determinano un doppio vincolo:
L'usabilità e l'utilità in un sistema di questo tipo risultano compromesse, soprattutto se la strategia è quella di una classificazione che soddisfi il prima possibile, magari già in homepage, le esigenze più popolari. Sembrano esserci allora motivi sufficienti per sposare la causa dell'incoerenza, come d'altronde fanno molti degli indici sistematici e dei portali della rete.
Tuttavia, per raggiungere questi obiettivi, è necessario allontanarsi per forza da schemi coerenti? Certamente no: le classificazioni a faccette, in quanto multidimensionali (diversi criteri di divisione possono essere applicati contemporaneamente), permettono di aumentare notevolmente il numero di esigenze di ricerca e di interrogazione soddisfatte, senza rinunciare alla coerenza. Lo consentono facendo dell'eccezione della categoria "By Region" di Yahoo! la regola.
L'interfaccia della categoria "Cars" di Epinions.com mostra come ciò si possa realizzare: le automobili sono classificate secondo i principi di divisione "Type", "Manufacturer", "Age", "Model Year", "Fuel Type" e tali faccette vengono poi esplicitate con chiare etichette. Sono così previste in un'unica pagina ben cinque diverse tipologie di esigenze. Gli utenti possono iniziare la ricerca dalla faccetta che più interessa loro: ognuno potrà trovare tutti gli item che rispondono a quella che considera essere la caratteristica più importante, senza l'obbligo di un unico percorso che parta da una faccetta specifica e senza dover controllare diverse sottocategorie. Il sistema garantisce infatti una pluralità di accessi, cioè una molteplicità di modalità di navigazione e di ricerca secondo principi di divisione differenti e, quindi, secondo bisogni informativi diversi. Si realizza così un ottimo sistema di accessi multipli.
Un'analisi a faccette molto approfondita, come d'altronde già precedentemente consigliato (cfr. sez. 2), è quindi sempre fortemente auspicabile. Ogni faccetta corrisponde a un tipo di esigenza degli utenti: eliminando un principio di divisione che potrebbe essere utile, non si permette più agli utenti di navigare lo schema secondo la corrispondente modalità di ricerca/esigenza.
Un'interfaccia analitico-sintetica può inoltre risolvere la questione delle categorie popolari: sotto l'etichetta della faccetta corrispondente non saranno elencati tutti i foci, soprattutto se troppi, ma solo quelli che si prevede verranno cliccati più frequentemente dagli utenti, magari ordinandoli proprio per popolarità e non sulla base di un criterio alfabetico. Se l'utente preferirà vederli tutti, potrà farlo in un secondo tempo (Epinions.com utilizza a questo scopo, come abbiamo precedentemente visto, il link "view more"). Nonostante tale possibilità, il numero di foci mostrato di default può essere anche elevato perché questi sono disposti nella pagina con una logica precisa, cioè dividendoli rispetto ai loro differenti principi di divisione.
In tali interfacce la coerenza della classificazione è infatti assicurata da una netta e chiara separazione delle classi a seconda delle faccette a cui appartengono. Come è già stato sottolineato nella sezione 1, la coerenza non è solo una proprietà che garantisce rigore e eleganza allo schema, ma è soprattutto un mezzo per facilitare la costruzione, da parte dell'utente, di un adeguato modello mentale dell'organizzazione del sito.
Inoltre, se i criteri di divisione vengono pure chiaramente mostrati, come fa Epinions.com, la classificazione diventa anche autoesplicativa e trasparente, risolvendo il problema, tipico di uno schema gerarchico-enumerativo classico, di non avere "una struttura esplicita tale da appalesare o da adombrare la teoria che esso incarna" (Serrai, 1977), la sua logica di ripartizione e i fundamenta divisionis impiegati in ogni livello della sua gerarchia. La familiarizzazione con lo schema non è più necessaria.
Riassumendo, si realizza quindi un sistema che prevede:
Aggiungendo a questa lista anche le proprietà, già evidenziate, di apertura, scalabilità, flessibilità e possibilità, senza controindicazioni, di cross-classification in fase di indicizzazione, è ora possibile cogliere tutte le potenzialità che l'applicazione al Web della teoria delle faccette comporta.
1. Ad esempio, si veda l'homepage del sito italiano di Fiat <http://www.fiat.it>.
2. Fortunatamente, alcuni schemi di classificazione tradizionali, come la Dewey, pubblicano attualmente piccoli aggiornamenti in rete, rendendo così più ristretti i tempi.
3. Tale livello di adattabilità di Yahoo! potrebbe però rendere difficile la familiarizzazione con lo schema di classificazione da parte degli utenti. La soggettività e l'arbitrarietà, inevitabilmente presenti, sebbene con gradi diversi, in tutti i tentativi di classificazione, rendono infatti necessaria una fase di apprendimento e di familiarizzazione se si vuole fare un uso completo e corretto dello schema.
4. Per approfondire le tematiche legate al concetto di "affordance" applicato al design (in generale e non solo in riferimento alla progettazione delle interfacce dei computer) si veda Norman (1988).
5. La categoria "Games" è infatti presente come rinvio in "Recreation".
6. Per esempio secondo Krug (2000) "agli utenti non importano i molti click finché ogni click è indolore e finché hanno la continua fiducia di essere sulla pista giusta".
La reperibilità delle risorse Web è stata verificata il 28 gennaio 2004.
Gnoli, Claudio 2002, Indicizzazione semantica nell'era digitale, testo dell'intervento presentato al 49' Congresso nazionale dell'AIB, Roma, 17 ottobre 2002, <http://www.burioni.it/forum/gnoli-sem.htm>.
Hunter, Eric Joseph 2002, Classification made simple, 2' edizione, Burlington (VT), Ashgate
Knowledge Management Connection 2002, "Conventional categorization. A complement to faceted classification", <http://www.kmconnection.com/Popularity-based_classification.htm>.
Krug, Steve 2000, Dont't make me think! A common sense approach to Web usability, Indianapolis (IN), Que (tr. it. Don't make me think! Un approccio di buon senso all'usabilità web, Milano, Hops libri, 2000)
MacLennan, Alan 2000, "Classification and the Internet", in Arthur Maltby e Rita Marcella (a cura di), The future of classification, Aldershot, Gower
Maltby, Arthur e Marcella, Rita 2000, "Organizing knowledge. The need for system and unity", in Arthur Maltby e Rita Marcella (a cura di), The tuture of classification, Aldershot, Gower
Mitchell, Joan S. 1998, "In this age of WWW is classification redundant?", in Catalogue and index, n. 127
Newton, Robert 2000, "Information technology and new directions", in Arthur Maltby e Rita Marcella (a cura di), The future of classification, Aldershot, Gower
Norman, Donald A. 1988 The psychology of everyday things, New York, Basic Books (tr. it. La caffettiera del masochista, Firenze, Giunti, 1997)
Risden, Kirsten 1999, "Toward usable browse hierarchies for the Web", in Hans-Jorg Bullinger e Jurgen Ziegler (a cura di), Human-computer interaction. Ergonomics and user interfaces, Proceedings of 8th International conference on human-computer interaction, Monaco di Baviera, Lawrence Erlbaum associates
Rosati, Luca 2003, "La classificazione a faccette fra knowledge management e information architecture (parte I)", It Consult, <http://www.itconsult.it/knowledge/articoli/pdf/itc_rosati_faccette_e_KM.pdf>
Rosenfeld, Louis e Morville, Peter 2002, Information architecture for the World Wide Web. Designing large-scale web sites, 2' edizione, Sebastopol, O'Reilly (tr. it. Architettura dell'informazione per il World Wide Web. Progettare siti web complessi, Milano, Hops Libri, 2002)
Rowley, Jennifer 1992, Organizing knowledge. An introduction to information retrieval, 2' edizione, Brookfield (VT), Ashgate
Saeed, Hamid e Chaudry, Abdus Sattar 2001, "Potential of bibliographic tools to organize knowledge on the Internet: the use of Dewey decimal classification scheme for organizing Web-based information resources", in Knowledge organization, Vol. 28, n. 1
Santoro, Michele 2002, "La disarmonia prestabilita. Per un approccio ibrido alla conoscenza e ai suoi supporti", in Biblioteche oggi, Vol. 20, n. 5
Scalisi, Raffaella 2001, Users. Storia dell'interazione uomo-macchina dai mainframe ai computer indossabili, Milano, Guerini e associati
Serrai, Alfredo 1977, Le classificazioni. Idee e materiali per una teoria e per una storia, Firenze, Leo S. Olschki
Steinberg, Steve G. 1996 "Seek and ye shall find (maybe)", in Wired, Vol. 4, n. 5
Veen, Jeff 2002, "Faucet facets. A few best practices for designing multifaceted navigation nystems", Adaptive Path, <http://www.adaptivepath.com/publications/essays/archives/000034.php>
Vizine-Goetz, Diane 1996, "Using library classification schemes for Internet resources", OCLC Internet cataloging project colloquium position paper, <http://staff.oclc.org/~vizine/Intercat/vizine-goetz.htm>
Weinberg, Bella Hass 1996, "Complexity in indexing systems - abandonment and failure. Implications for organizing the Internet", testo dell'intervento presentato allo ASIS 1996 annual meeting, Baltimore (MD), 19-24 ottobre 1996, <http://www.asis.org/annual-96/ElectronicProceedings/weinberg.html>.
Zins, Chaim 2002, "Models for classifying Internet resources", in Knowledge organization, Vol. 29, n. 1